Next-Level AI Agents Powered by Realistic Training Data and Scalable Architecture
Salesforce AI has released two game-changing innovations—APIGen-MT and the xLAM-2-fc-r model family—that significantly advance the training and performance of AI agents. These new tools address a longstanding challenge in AI development: how to build agents that excel in multi-turn, goal-driven interactions within complex domains like customer support, finance, and retail.
Unlike conventional chatbots, intelligent AI agents must maintain context over several exchanges, interpret user goals in real time, and interact with external tools and APIs. These agents must adapt across conversation turns, perform tasks, provide feedback, and align with dynamic procedural rules. However, training such agents has been hindered by a lack of high-quality, verified, multi-turn interaction datasets.
The Core Challenge: Training AI for Complex, Realistic Conversations
Creating datasets that mimic real-world task flows is time-consuming, expensive, and requires domain expertise. Traditional data pipelines either rely on synthetic data that lacks realism or rule-based systems that fail to generalize. Even top-performing models like GPT-4o or Claude 3.5 often struggle to maintain context or handle tool-based executions effectively without such data.
Introducing APIGen-MT: Structured, Scalable, and Verified Data Generation
APIGen-MT, developed by Salesforce AI Research, revolutionizes synthetic data creation through a robust two-phase pipeline:
Phase 1: Task Blueprint Generation
Using a large language model (LLM), the system proposes user goals, groundtruth actions, and expected outputs. These are validated for formatting, feasibility, and accuracy using automated tools and LLM-based review committees. Failed tasks trigger feedback loops for refinement.
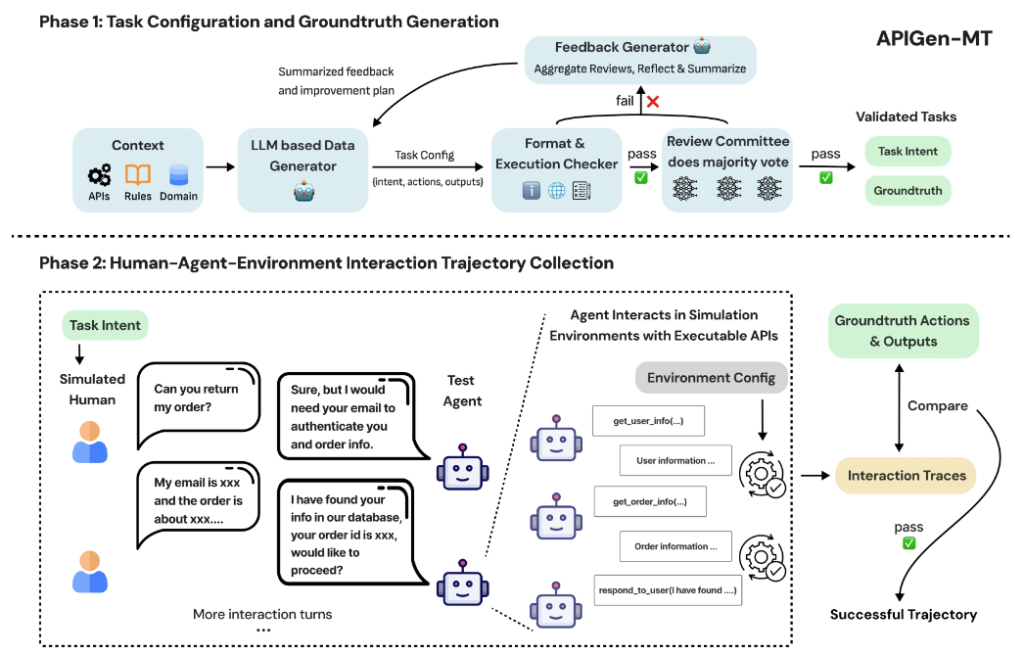
Phase 2: Simulated Human-Agent Dialogues
Validated tasks are used to simulate multi-turn dialogues where agents execute tasks by calling APIs, interpreting responses, and evolving conversations in realistic ways. Only high-fidelity, executable dialogues are retained, ensuring clean, coherent training samples.

xLAM-2-fc-r Models: Built for Multi-Turn Mastery
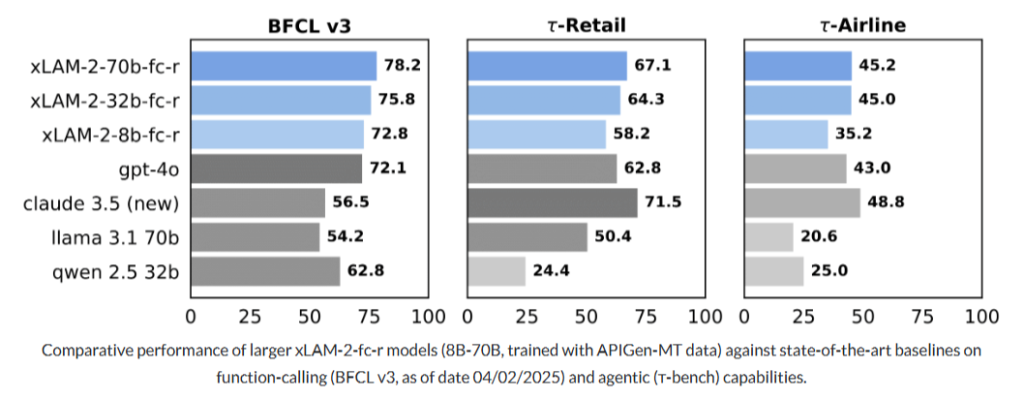
Trained on the APIGen-MT dataset, the new xLAM-2-fc-r model series—ranging from 1B to 70B parameters—outperforms leading models in multi-turn agent benchmarks:
- Retail (BFCL v3): xLAM-2-70b-fc-r scored 78.2, surpassing GPT-4o (72.1) and Claude 3.5 (56.5).
- Airline Domain: Scored 67.1, outpacing GPT-4o (62.8).
Smaller models like xLAM-2-8b-fc-r also beat larger counterparts in long-turn interactions, showcasing efficiency and robustness, critical for enterprise-grade deployments.

Why This Matters: Verified Data > Bigger Models
Salesforce’s approach proves that verified, context-rich training data is more valuable than model size alone. The models trained on APIGen-MT data show improved goal alignment, tool usage, and dialogue flow, particularly in complex, procedural conversations.
Key Innovations and Benefits
- Multi-Turn Agent Datasets: Grounded in realistic, goal-driven tasks.
- Feedback-Driven Learning: Failed generations are refined using review loops.
- Executable Interactions: API calls and tool use are validated step-by-step.
- Benchmark-Beating Models: xLAM-2-fc-r outperforms even GPT-4o in multiple domains.
- Open-Source Impact: Salesforce is releasing both the data and models to democratize AI agent research.
- Enterprise-Ready: Robust performance across trials ensures reliability in business scenarios.
Final Thoughts: A New Era for AI Agents
With APIGen-MT and xLAM-2-fc-r, Salesforce sets a new benchmark in AI agent development. These innovations combine data accuracy, structured validation, and scalability to enable intelligent, tool-using agents capable of handling real-world tasks with precision.
Whether you’re building AI for customer service, financial advising, or complex knowledge tasks, these new tools provide a foundation of verified interaction data and high-performance models that deliver consistent results.
Check out the Paper and Model. All credit for this research goes to the researchers of this project.